|
Amir Sariri Rotman School of Management, University of Toronto Peter Wittek ICFO-Institut de Ciencies Fotoniques, The Barcelona Institute of Science and Technology Just five months after I had started working with my doctoral supervisor on an economic research project on the labour market for AI scientists, I came across a term that seemed intellectually “cool,”, but about whose scientific or technological meaning I was clueless - Quantum Machine Learning (QML). As a by-product of documenting research in artificial intelligence for several months, I had learned about various streams of AI research, especially Machine Learning. While trying to narrow my research questions, I could not resist thinking about how quantum machine learning is different from its classical version. Having Peter Wittek, a mathematician and QML researcher as a Chief Scientist of the Creative Destruction Lab (where I am a research fellow) made me think it would have been a shame if I did not collaborate with him to write an article on the latest advances in QML research. We sat together and decided to write this article with some light technical detail for those interested in this area as a future field of research or as a source of advanced technologies for startup ideas. In this article, we avoid unpacking quantum physics phenomena such as superposition and entanglement that are foundational to understanding how quantum computers work. Instead, we aim to describe the current state of research in quantum machine learning. We will explain some of the challenges researchers face in the quantum computing arena and briefly review some of the viable solutions to tackle those challenges. In some cases, we will also recount examples of hardware and platform developments by the industry that are relevant to these challenges. The transformative role of computer science has long been documented as the precursor to much of the scientific progress and economic growth in the modern world. We have come a long way since Alan Turing’s contributions to computer science and cryptanalysis in 1936, which laid the foundation of modern computers. However, scientists’ imagination has always been bounded by computational power: the speed and efficiency at which a number is calculated, or a problem is solved. Ideas for more efficient ways of solving scientific problems have been ahead of the state-of-the-art in computer technology. The three-billion-dollar Human Genome Project to determine the DNA sequence of the entire human genome provides a tangible example. Although the project was declared complete in 2003, scientists only had the faintest glimmer of what their information was really telling them, especially because they were immersed with large volumes of data that could take years to process and analyze. Diseases such as cancer each may have millions of DNA rearrangements compared to a normal cell, and even today we cannot fully read these rearrangements and process our readings fast and efficiently. A major barrier to sequencing more personal human genomes and analyzing this data has been computational power. The cost of data storage and efficiency of algorithms that processed data play a role, but computer speed has been the bottleneck. Demand for higher computational power has always exceeded the supply. Gordon Moore’s 1965 observation was that the number of transistors in each square inch of computer chips doubled approximately every 18 months; he predicted the doubling of computational speed every two years. The slope of progress in many fields of science that rely on computers, including genetics in the example above, has been characterized by Moore’s observation. Skeptics accurately predicted that this trend would be too optimistic in the long run. Physicists, too, told us how the laws of nature will put an end to this trend, since transistors cannot get smaller than the size of atoms. The demand today is, again, solving problems that cannot be efficiently solved by classical computers, which are becoming very hard to improve in terms of speed and efficiency. Hope was found three decades ago in quantum physics: computers that exploit quantum effects to compute certain problems faster. The idea is to imagine solving problems that are effectively impossible to solve with classical computers or that would take as long as a few hundred years on a modern supercomputer. An efficiency gain of this magnitude would be hard to dismiss, and a vast number of scientists, corporate research labs and government initiatives from around the world have focused their attention on processing information by taking advantage of quantum phenomena. At the same time, we’ve observed major advances in machine learning techniques and a rapidly growing number of scientists who have focused on taking advantage of quantum effects to enhance machine learning. Quantum machine learning is the intersection of quantum information processing and machine learning. As a conceptual framework, think of it as a Venn diagram, where we have machine learning as one circle, quantum information processing as another, and the intersection of the two defines quantum machine learning (see “Quantum Machine Learning”, by Biamonte, Wittek, Pancotti, Robentrost, Wiebe and Lloyd). The scale of today’s information processing requirements pushes us to depart from laws of classical physics and resort to quantum physics to help us store, process, and learn from this data. 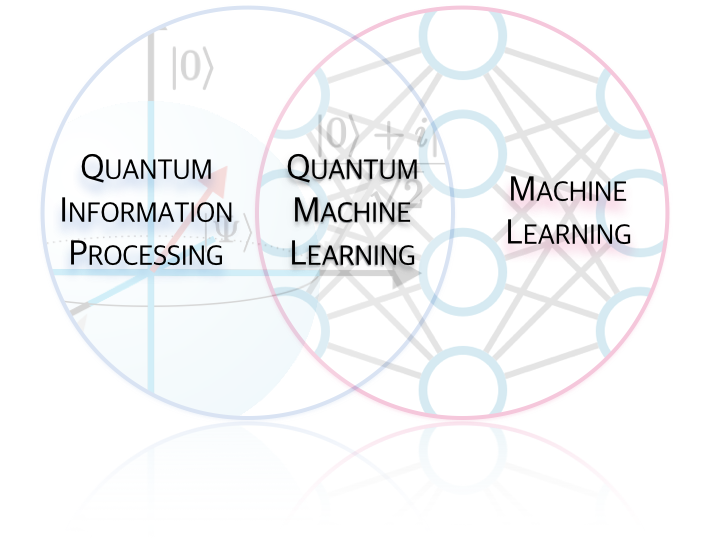 Representation of quantum machine learning research as a combination of research in quantum information processing and machine learning. One way to understand scientific work on quantum machine learning is to think of it as a two-way street. On the one hand, machine learning helps physicists harness and control quantum effects and phenomena in laboratories in order to better understand quantum systems and their behavior. On the other hand, quantum physics enhances performance of machine learning algorithms that are difficult to use with classical computers. The focus of this article is on the latter: quantum enhanced machine learning. The value proposition is clear; quantum versions of machine learning can learn from data faster and with higher precision, producing more accurate predictions. This quantum version of ML algorithms, however, happens to be harder to implement than it sounds.
First, due to the peculiar nature of how a quantum computer works, it is challenging to input classical data such as financial transactions or pictures. One way to tackle this problem is to use “quantum data”; it is much easier to deal with data that is already quantum, such as information about the inner working of a quantum computer or data that is produced by quantum sensors (i.e. sensors that produce data in quantum state). Another way is to perform what is called a quantum state preparation of the classical data. One way that scientists can do this in laboratories is to use polarization of photons in order to encode zeros and ones of classical data into physical degrees of freedom required for quantum processing of the data. The second challenge is quantum computers do not speak the languages that most programmers are familiar with (e.g. Python, C#, Javascript). In fact, programming quantum computers for efficient processing of data turns out to be more complicated than simply developing a new programming language. Nevertheless, basic quantum programming languages are evolving; Microsoft’s LIQUi|> (read “liquid”) is one of them, developed by Quantum Architectures and Computation Group at Microsoft Research. The full platform is available on GitHub. IBM Q, an IBM initiative to build commercial quantum computers, has its own graphical language platform called Quantum Experience whereby users can run algorithms on IBM’s quantum processor and work with individual qubits. We have also made improvements on computing paradigms. For instance, D-Wave’s quantum annealer is not a universal quantum computer, which means it cannot run any of the mentioned quantum programming languages, yet the hardware is useful for learning from data faster than with classical computers. Finally, after researchers have successfully fed quantum machines with data that it can read, and also written and implemented algorithms to process their data, they still have a problem: it is often hard to read the results accurately. The result of quantum operations is a quantum state, which can be thought of as a special probability distribution. Obtaining classical information about the quantum state requires “measurement”. To fully characterize a quantum system (i.e. obtain the results), a researcher would have to repeat the measurement (and quite possibly all computations that led to the state), just like when she is sampling an unknown probability distribution. They need to do this repetitive task in order to understand what the quantum system did to the data, and to be able to have a classical interpretation of the results. These challenges will require substantive work as QML transfers from research laboratories and into science-based startups. Going back to my research on the trajectory of artificial intelligence from an ignored idea in 1970s to one of the most exciting sources of scientific research and core technology of startups today, QML has the potential to bring about the next wave of technological shock and create a step function reduction in the cost of prediction (see “The Simple Economics of Machine Learning”, by Ajay Agrawal, Joshua Gans and Avi Goldfarb). Both machine learning and quantum information processing are rapidly growing and have their own uncertainties. Quantum machine learning is a space where these two strands of research act as complements of each other and every step forward in one is an opportunity of improvement in the other. Some of the complexities and challenges stated above are easier to manage when the goal is to build intelligent systems that learn from data. In addition, machine learning may itself enable scaling up quantum information processing, which can eventually lead to building scalable quantum computers. While collecting and storing vast amounts of data are becoming so cheap that it is no longer a concern, machine learning community is coming up with faster and more efficient methods and techniques to learn from this data. What determines how fast we capitalize on our data and models is computational power, and quantum machine learning is showing the much promise needed in order to be our best bet yet for building both intelligent systems and quantum computers.
4 Comments
|
Archives |
 RSS Feed
RSS Feed
